Le schede grafiche HPC della serie AMD Instinct MI200 attirano l’attenzione con la loro potenza di calcolo bruta. Questo è anche, ma non solo, l’approccio multi-chip che combina due GPU in un’unica GPU. white paper ufficialePDF) Ora maggiori dettagli. Panoramica.
Annuncio: la settimana del Black Friday inizia a Saturno, SanDisk Ultra 3D SSD da 2 TB Invece di 189,99 euro Acquista solo 139 euro!
MI200 lascia MI100 molto indietro
La serie Instinct MI200 è disponibile in tre versioni: MI250X e MI250 in figura Modulo acceleratore OCP (OAM) e l’MI210 nel formato della scheda PCIe aggiuntiva. Il modello top di gamma è almeno due volte più veloce del suo predecessore, l’Instinct MI100 basato su CDNA 2.
-

Instinct MI210 seguirà “presto” in formato PCIe (Foto: AMD)

foto 1 da 5
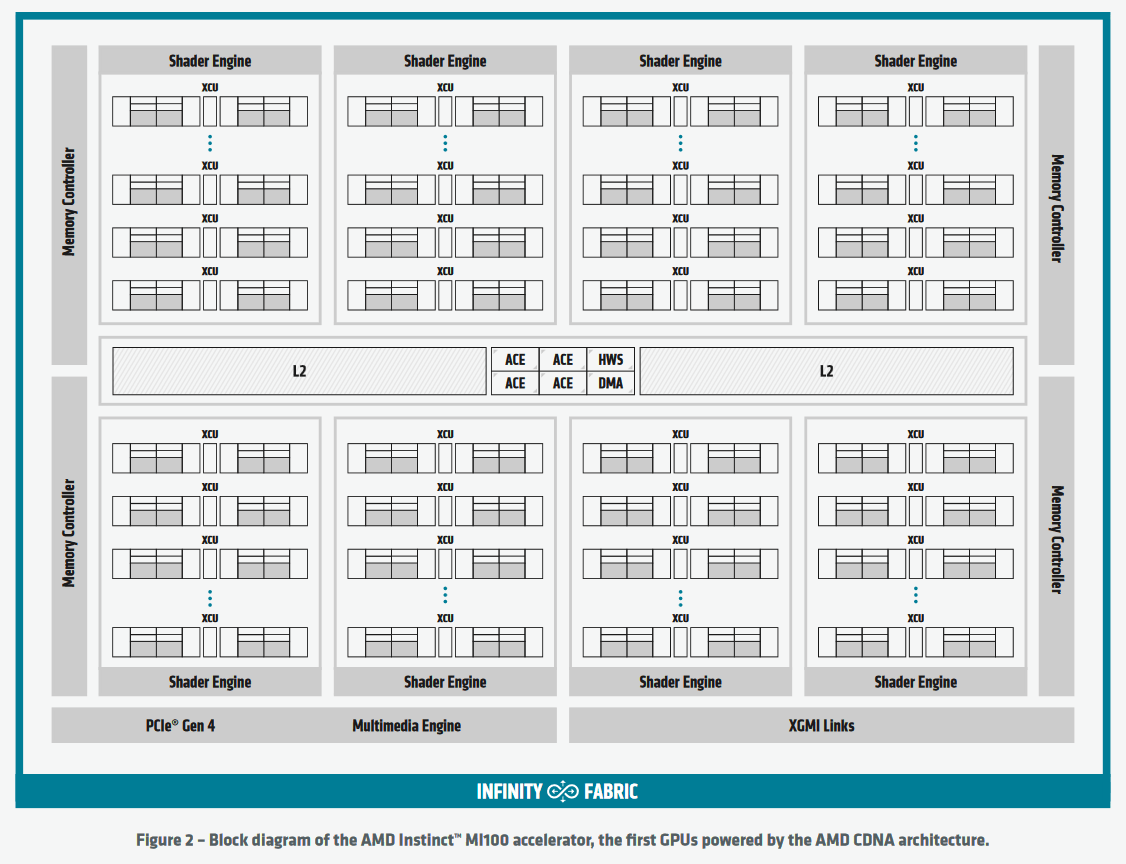
Era già noto in anticipo che AMD ha reso questa esplosione di prestazioni ampiamente possibile utilizzando due modelli computazionali grafici (GCD) sullo stack GPU. Il numero di CU per GCD è 110, che corrisponde a un totale di 220 CU, mentre il numero di CU MI100 è 120. Secondo il white paper, la composizione completa del GCD è di 112 unità monetarie.
Un leggero e incrementale aumento della frequenza di clock aumenta le dimensioni delle prestazioni dell’FP32 di un fattore di 2,1 volte con il 9% in meno di CU per GDC. Tuttavia, in altre aree, le prestazioni aumentano ancora di più di un fattore 4. Il white paper rivela in dettaglio cosa c’è dietro.
CDNA 2 offre piena velocità con FP64
A prima vista, ci sono stati solo cambiamenti graduali a livello di unità di business. In realtà è stata scelta una struttura per il CDNA dello scorso anno, simile a RDNA 2, inserendo alcuni elementi tra i due gruppi ALU, mentre il resto è rimasto lo stesso con GCN. I miglioramenti di CDNA 2 rispetto a CDNA possono essere visti nelle ALU. I moduli di calcolo sono stati ampliati e accelerati in molte delle loro funzioni.
-

Modulo di calcolo CDNA 2 (MI250)
foto 1 da 4
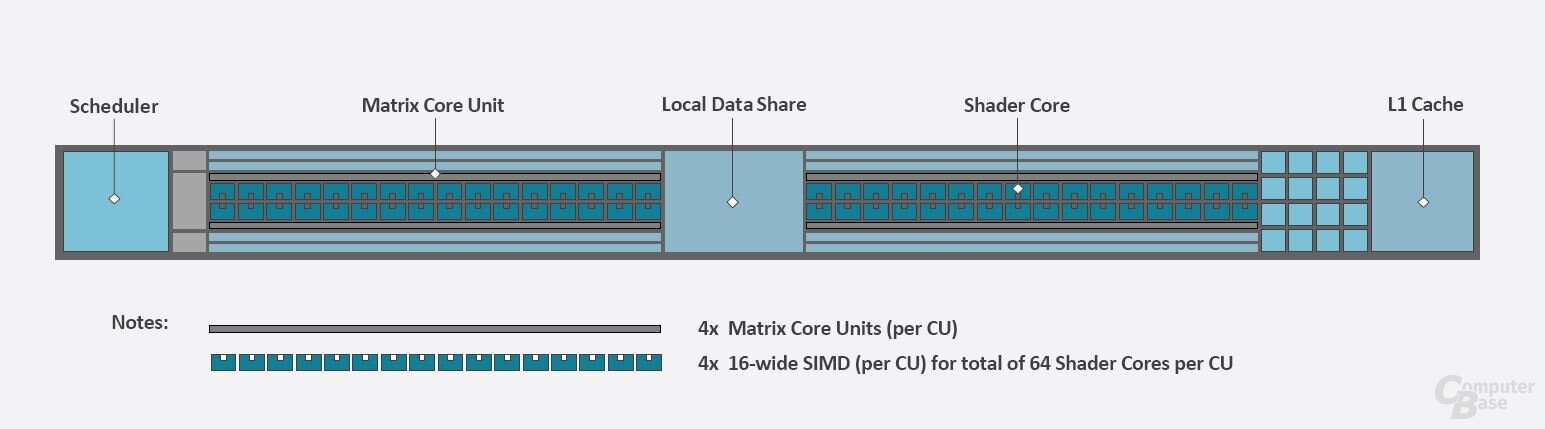
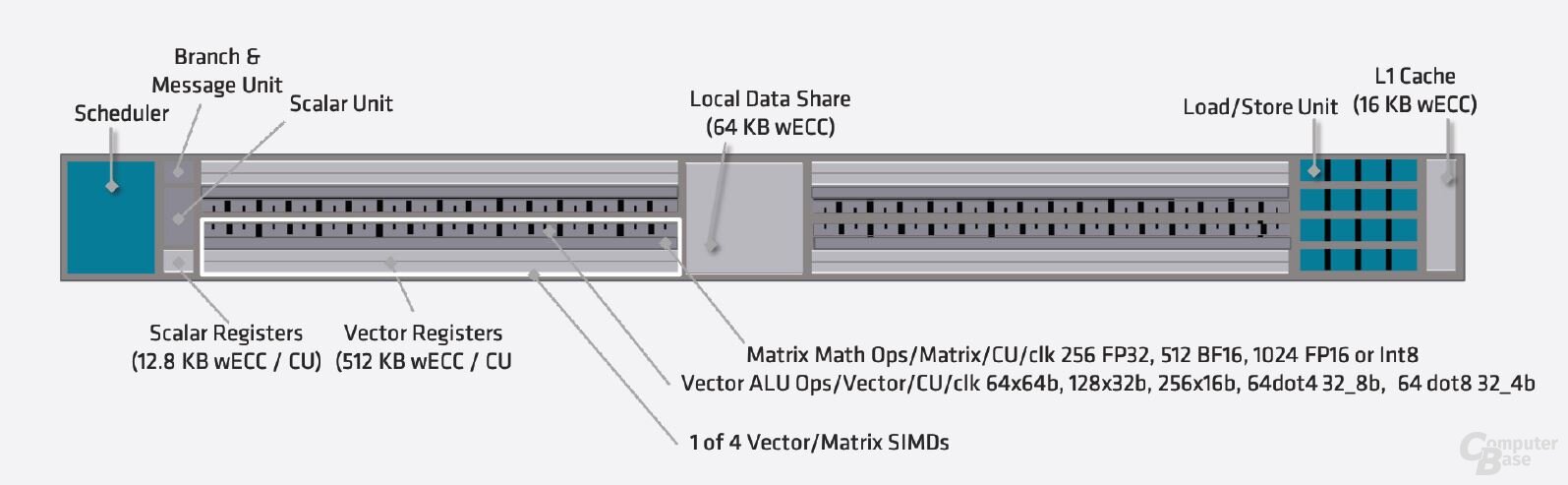


Tradizionalmente, le GPU sono state progettate per la massima potenza di calcolo con FP32, la cosiddetta precisione semplice. I numeri MI100 sono stati elaborati utilizzando FP64, ovvero 64 bit per numero e quindi doppia precisione, solo a metà della velocità di registrazione e quindi dell’area del chip. Il rapporto 1:2 tra FP32 e FP64 era ancora un chiaro segno della GPU del server, poiché la GPU consumer relativamente riconfigurata Radeon VII funzionava a 1:4 e il predecessore Vega 64 a 1:16.
Questo è diverso con l’MI200. Le ALU FP64 sono progettate da zero ed elaborano i calcoli FP64 in un rapporto 1: 1. A questo scopo, i registri sono stati espansi in modo che ogni ALU possa elaborare direttamente un numero FP64. Con 128 unità aritmetiche per console che producono 128 flop per unità di valuta all’ora, il doppio rispetto a MI100 e MI50.
Rapid Packed Math può aumentare l’accelerazione FP32
Registri di grandi dimensioni offrono un ulteriore vantaggio: utilizzando Rapid Packed Math (RPM), è possibile eseguire due calcoli FP32 contemporaneamente per ciascuna ALU utilizzando il codice appropriato. AMD fornisce esempi di modifiche al codice necessarie nel white paper (PDF). Di conseguenza, le prestazioni massime dell’FP32 sono il doppio di quelle dichiarate da AMD sul chipset. Nelle applicazioni giuste, AMD a volte è molto più avanti della concorrenza.
I nuclei della matrice AMD rispetto ai nuclei del tenditore
Appena sotto il radar, AMD ha già introdotto i core a matrice di prima generazione in CDNA, che, come i core tensori di Nvidia, velocizzano le operazioni a matrice e svolgono particolarmente bene le attività di intelligenza artificiale. In CDNA 2, AMD ha ampliato i calcoli BF16 e la nuovissima voce per le operazioni con matrici FP64. Come con le prestazioni tradizionali dell’FP32 con RPM, questo aumento ha il doppio della potenza di calcolo di un altro di un fattore di 4,2.
Diventa interessante confrontare la potenza di calcolo di una singola unità di matrice con la potenza dei nuclei tensoriali tra generazioni diverse. I moduli a matrice di prima generazione di AMD erano già significativamente più veloci e posizionati in modo più ampio in termini di funzionalità rispetto ai core tensionatori di prima generazione di Nvidia nell’acceleratore Volta V100. Rispetto ai core tenditori di terza generazione nelle GPU, anche i core matrix ottimizzati per AMD sono significativamente più deboli. Solo il doppio del numero (880 rispetto a 432) e la frequenza di clock più elevata (1700 MHz rispetto a 1410 MHz) assicurano che AMD sia alla pari in alcune aree. Con l’avvento della prossima generazione di GPU per server Nvidia, Nvidia potrebbe ancora una volta sfruttare l’intelligenza artificiale.
Il calcolo grafico muore in una singola GPU
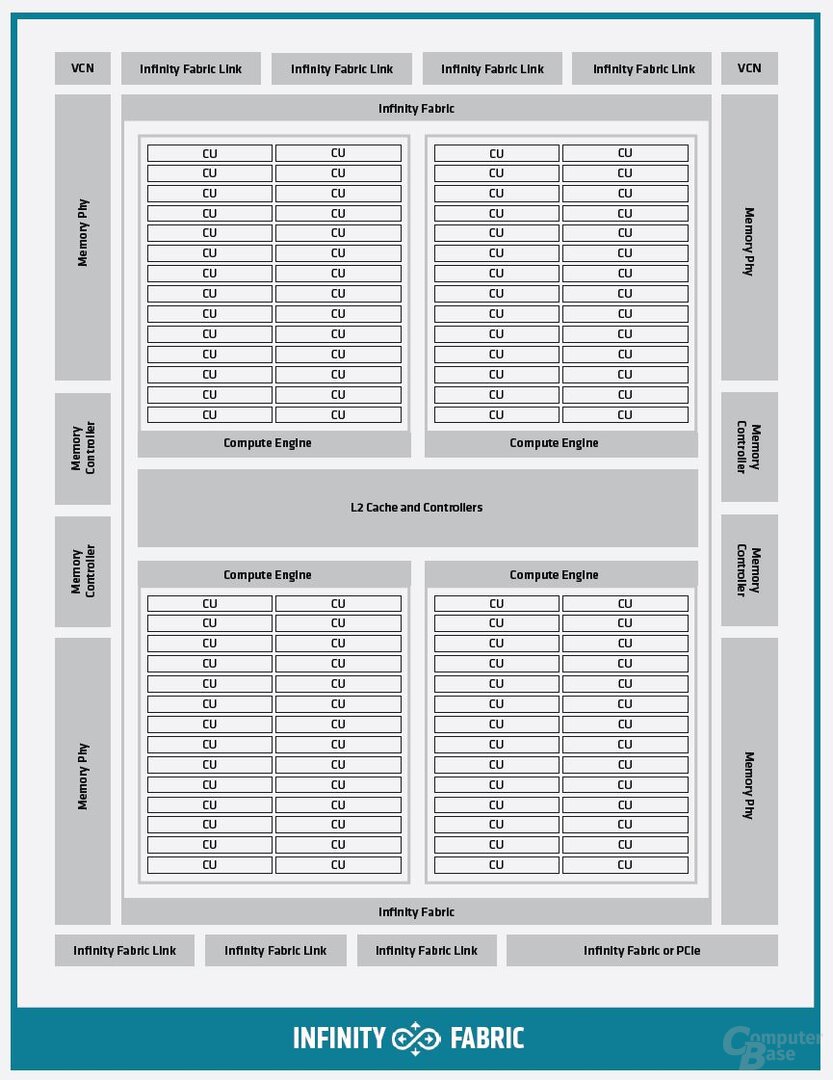
Rispetto al chip MI100, la struttura del GCD è sostanzialmente invariata. Anche qui le innovazioni sono più nei dettagli. La larghezza di banda della cache L2 per ogni GCD è stata più che raddoppiata a poco meno di 7 TB/s mantenendo la stessa dimensione di 8 MB. A tal fine, sono stati utilizzati algoritmi di distribuzione dei dati nella cache L2 per massimizzare il throughput di FP64 in operazioni atomiche Intensificatore.
CDNA 2 contiene anche diversi collegamenti Infinity Fabric oltre a una tipica connessione PCIe, che garantisce la comunicazione sia con il secondo GCD sulla stessa GPU sia con altre GPU nel sistema. Infinity Fabric funziona fino a 400 GB/s tra due GCD e tra più GPU in un sistema da 100 GB/s ciascuna (50 GB/s bidirezionale) e quindi fino a 800 GB/s.
AMD parla di una connessione coerente con la cache, che è controllata dal processore AMD Epyc di terza generazione, a cui però è consentito utilizzare solo l’MI250X. La CPU del server può accedere a ogni bit della VRAM e utilizzarla come cache con la GPU. Le GPU ricordano le parti della VRAM attualmente condivise con la CPU per evitare colli di bottiglia delle prestazioni. Lo spazio degli indirizzi che una GPU può gestire è sufficiente per 4 petabyte di memoria fisica e 128 petabyte di memoria virtuale. In un nodo con un massimo di 8 schede di accelerazione, ogni GCD deve essere visualizzato sul sistema come GPU indipendente.
È interessante notare che sia CDNA che CDNA 2 contengono decoder video (“Multimedia Drive” o “VCN”), sebbene non ci siano connessioni per monitor. Secondo AMD, possono essere utilizzati per alimentare le attività di apprendimento automatico direttamente con materiale video e immagine, che viene quindi decodificato sulla scheda in tempo reale. Supporta decoder video VP9, HEVC, AVC e JPEG.
-

MI200 . schema a blocchi
foto 1 da 2

“Esploratore. Scrittore appassionato. Appassionato di Twitter. Organizzatore. Amico degli animali ovunque.”